
这是 前一篇文章 的后续。通过一段时间的学习 对cuda编程有了一定程度上的认知,趁着有闲暇时间 完成之前挖的坑。顺便更新博客 分享我的一些经验。以下论述模型默认使用mnsit开源手写数字集作为验证。而其输入为 28 * 28 输出为 10。
该项目同样是开源项目:
开源地址:Talentjoe/CudaNN
前一个项目(cpu版本):Talentjoe/SimpleNeuralNetwork
1. 程序优化
从上次更新到现在 程序进行了几次优化,陈列如下:
- 最重要的当然是 使用cuda重构了前向传播和反向传播的代码,使用cuda kernel作为主要的计算单元 大大提升了计算效率。经过对比 784, 300, 10 的推理和训练速度有大约7倍的提升 (相较于cpu版本)。在较大规模的推理及训练中能有更多的提升(测试使用 784, 1024, 10有约30倍的提升 当然该对比是不严谨的 cpu使用的是double精度 而cuda使用的为float精度)。而在与成熟模型训练的不严谨的对比下,训练速度约为pytorch同尺寸的1/2,还是较为满意的。(并不严谨 仅是使用相同数据集与相同激活函数与模型参数 并未考虑其他因素)
- 加入了激活函数的选择功能,经过一些学习后发现之前仅仅使用sigmod作为激活函数的方式欠妥,这也导致了深度较大的模型在训练的某些时候无法拟合。因此重构了激活函数的逻辑,使得用户可以在创建模型时自由选择激活函数。代码默认添加了ReLU 作为激活函数,同时,该框架可以较为简单的增加其他激活函数。
- 重构代码结构 以此适配cuda kernal。自定义Vector与Matrix结构体,更为方便的管理cuda计算信息。同时启用vector理论上对空间有所优化。优化了代码逻辑以及逻辑结构。
数据仍然使用MNSIT 数据集 并且使用之前编写的库进行读取 未做任何优化。
2. 优化过程
个人认为c++ cuda编程还算友好 但缺少相关的学习资料,学习曲线不够平滑。我使用的是 freeCodeCamp.org youtube课程 作为入门教程 以及初始印象积累 并且配合 cuda官方编程手册 (新手很不友好 在看过youtube课之后才有点明白)进行的编程,当然 也使用了AI工具作为辅助。
由于编写该项目的目的是为了了解cuda编程以及更加深入的了解NN,因此并未使用cuda的第三方库。
对于我这个项目来说 cuda更像是parallel for的多线程优化,我做的尝试是将部分的for循环使用cuda kernel代替,以此减少cpu时间 加速进程。
由于cuda特性 cuda仅能运行由 __gloable__ 以及 __device__修饰的函数 且该函数不能为类的成员函数,因此需要单独为cuda运行编写单独的函数 再通过全局调用 进行计算。因此引入单独文件专门用于编写可能用到的cuda函数 并且进行部分重构将help functions转移其中。另外 由于cuda 使用的数据需要额外的步骤从cpu中传输到gpu中 且在不使用其他库的前提下 仅支持基础c格式的数据结构,无法便捷的将std vector转移到其中,为了代码简洁,我编写了自己的Vector以及Matrix。结构体中记录了 其大小(对于vector为size matrix则为width 以及 height),cpu中的数据指针,以及gpu中的数据指针;同时 结构体提供了一些方法 包括,resize,从cpu向gpu中拷贝信息,从gpu向cpu中拷贝信息(拷贝方式包括同步及异步),使用cuda使用随机数初始化数组信息。在这种构架下 能够方便的将cpu及gpu信息同步,方便debug。
由于期望实现在不同层之间使用不同激活函数 且希望计算过程在gpu上进行,所以需要在计算中将激活函数传入,在AI的帮助下,采用了不那么优雅但是有效的方式。如下方代码 ReLU 的定义,需要定义名称为ReLU的结构体,并且重新定义”()“运算 并且将他设置为__device__ 在传入函数的时候 即可通过传入结构体 来实现激活函数的选择。
struct ReLU {
__device__ float operator()(float x) const {
return max(x, 0.0f);
}
};在编写kernel的时候 使用模板即可 如:
template<typename ActFun>
__global__ void activate_kernel(Vector layerZ, Vector layer, ActFun af) {
int id = blockIdx.x * blockDim.x + threadIdx.x;
if (id < layerZ.size) {
layer.d_elements[id] = af(layerZ.d_elements[id]);
}
}
//调用
activate_kernel<<<gridSize,blockSize,0,stream>>>(layersZ[i + 1], layers[i + 1], sigmoid());
3. 部分成果
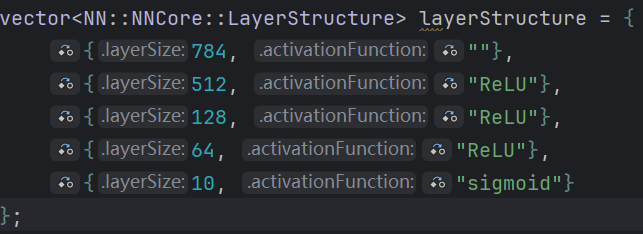
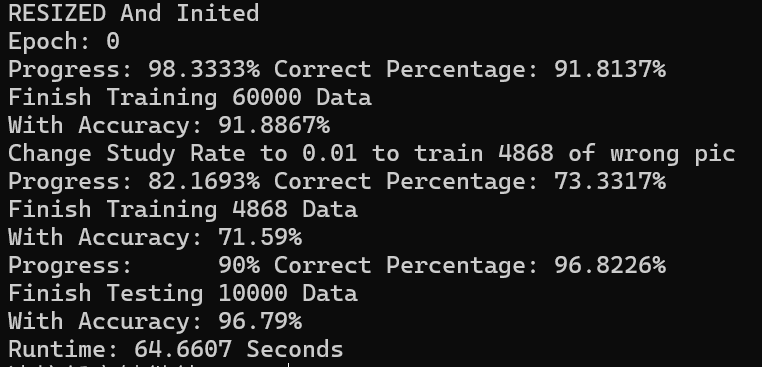
使用cuda重写后 最大的提升是速度的增加。使用 784 512 128 64 10 的模型结构 训练60000数据集 仅需60秒左右。反之使用cpu进行计算 这么大的数据量甚至无法完成。
cuda的优势在于大量的并行运算,因此 784 512 128 64 10 的计算与 784 512 256 64 10 甚至更大的计算量并无本质区别,而相较而言对于cpu来说 则是几何倍数的提升,会大大减缓速度。
作为对比 使用cpu进行 784 100 10 的训练需要约170秒 而 784 300 10 则约需要600秒。cuda进行对应训练 则分别需要 20秒 与 27秒。相比而言 cpu使用了约3倍的时间 而cuda仅使用了 约1.35倍的时间。以此来看 并行计算 及cuda在大规模应用中也是极有优势的。
在增加激活函数的选择后,激活过程更加合理,保留了更多信息,因此可以训练更深的模型 并且达到更低的cost。通过增加Relu激活函数 也能达到更亏的收敛速率。在模型为 784 200 200 200 10 的情况下,使用sigmod函数作为激活函数 在第一轮60k的数据训练完后准确率仅达到 91.91% 第二轮达到约 93.9267%,且最终收敛后的准确率在约 96.7%。而在换用ReLU作为激活函数后 使用相同study rate 能够在第一轮训练后达到94.07% 的准确率 第二轮即可达到 96.5% 而最终收敛于 97.5%。(具体训练输出可以查看一下pdf)
在速度提升及加入ReLU激活函数后,能够在短时间内使用更大的模型参数量 训练更多轮次 获得更多的调参机会;同时可以使用更大的模型参数 以此可以达到更高的准确率。在经过一段时间的调优后 在使用动态学习率 784 512 128 64 10 作为模型大小的前提下 达到了测试集98.1%的准确率。个人对于这个结果较为满意,相较于之前的nn模型 准确率提升了 约5%。成为了较为可用的模型。
测试集达到98.1%的模型可以通过该链节下载 下载链接。开源项目中有读取示例,模型定义为:
第一行 层数 n
第二行 每层参数量 k_i
第三行 各个激活函数名称
后 n 行 每层bias值
再后 n 行 每层weight值
通过激活及计算后即可得到对应数字概率。
4. 遇到的困难
在编写代码和测试的过程中也遇到了很多问题,我将其列出 如果有人遇到相同问题可以以此作为参考。
- relu函数的w的初始化:
最开始将relu作为激活函数的时候,模型效果极差 准确率仅有约10%。当时考虑的是代码编写出现了问题 因此检查了很多遍 但是并未发现问题。经过搜索资料以及询问ai,发现该问题出现在初始化w值的过程中,由于之前使用的sigmod函数 初始化的参数被设置在了-1到1之间。但是实际上该参数应该随着模型大小 层数的变化而变化 应当被设置为 位于 -sqrt(const/层节点数) 到 sqrt(const / 层节点数) 之间。个人猜测与ReLU函数 在0到正无穷的导数为常数 且 函数值为单调递增。如果传入过高的参数 会导致推理时后半部分出现极大值 进而造成需要较长时间才能回到预期值, 而又因为relu在负数区间为0 在回归预期值的过程中 容易造成神经元失活 因此对初始值很敏感。而相交而言 sigmod就不那么敏感。(以上仅为猜测 暂未进行验证) - cuda函数传入
Cuda仅能调用带有 __gloable__ 或 __device__ 修饰的函数,这导致更改激活函数变的困难。目前仅能想到使用struct方式 再重定义括号算法。我也尝试过使用继承 但是cuda无法正常解析。 - to be continue
5. 仍有不足 未来优化
当前仍然有很多可以优化的地方,首先是在推理的时候,其实可以并行很多计算,通过矩阵相乘,可以一次性进行大规模推理。但是目前并未实现 只能一个一个进行推理。
同时该模型仅为全连接的神经网络,并未实现卷积。如果有机会 我会考虑加入卷积 以此来看是否可以更好的完成目标。
目前尝试简单手写了一个qt的手写板程序 可以读取模型 并且猜测手写的内容,但是目前效果不是很好,无法达到推理集一集测试集的准确率,我认为这和数据归一化有关系。而且目前qt的实现十分简陋 还需要更多的优化 编写仅供参考。
《“[开源项目]带有cuda加速 神经网络”》 有 1 条评论
🐂